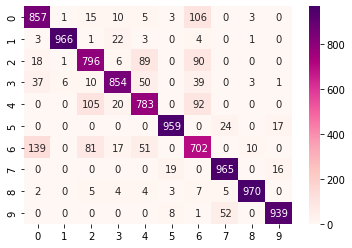
# 어떤것을 많이 틀리는지 확인한다. # 이런것은 컨퓨전 매트릭스로 확인하는 것! from sklearn.metrics import confusion_matrix y_pred = model.predict(X_test) y_pred.shape # 테스트 이미자가 10000개 (10000, 10) # 출력 y_test[0] 9 #출력 y_pred[0] # 출력 array([4.27080568e-06, 1.02400215e-07, 6.76651825e-06, 5.95587892e-07, 2.32840534e-06, 1.21201472e-02, 4.48114770e-06, 1.23955883e-01, 3.06501424e-05, 8.63874733e-01], dtype=float32) y_pred[0].argm..